随着大数据技术的快速发展,Spark作为一种高效、可扩展的分布式计算框架,已在数据处理领域占据重要地位。它不仅能够处理大规模数据集,还提供了丰富的API和库,支持多种数据处理任务。本文将重点介绍Spark的核心特性、数据处理流程及其在实际应用中的优势。
一、Spark的核心特性
- 高速计算能力:Spark通过内存计算技术大幅提升了数据处理速度,相比传统的MapReduce框架,其性能可提升数倍至数十倍。这得益于Spark的弹性分布式数据集(RDD)模型,允许数据在内存中进行多次迭代计算,减少了磁盘I/O开销。
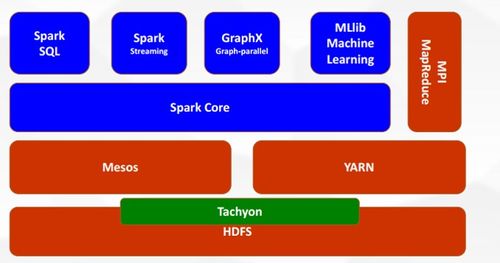
- 易用性:Spark提供了多种编程语言的API,如Scala、Java、Python和R,使得开发人员能够快速上手。Spark还集成了高级库,如Spark SQL用于结构化数据处理,Spark Streaming用于实时流处理,MLlib用于机器学习,GraphX用于图计算,满足了多样化的数据处理需求。
- 容错性:Spark通过RDD的 lineage(血统)机制实现容错。当某个节点失败时,Spark可以根据血统信息重新计算丢失的数据分区,而无需将数据复制到多个节点,从而提高了系统的可靠性。
- 可扩展性:Spark可以运行在多种集群管理器上,如Apache Mesos、Hadoop YARN或Spark自带的独立集群模式。它能够轻松扩展到数千个节点,处理PB级别的数据,适用于企业级的大规模应用。
二、Spark的数据处理流程
Spark的数据处理通常遵循以下步骤:
- 数据输入:Spark可以从多种数据源读取数据,如HDFS、本地文件系统、Apache Kafka、Amazon S3或关系型数据库。通过SparkContext或SparkSession,用户可以加载数据并创建RDD、DataFrame或Dataset对象。
- 数据转换:Spark提供了丰富的转换操作(如map、filter、reduceByKey),允许用户对数据进行清洗、聚合或转换。这些操作是惰性执行的,只有在触发行动操作(如count、save)时才会实际执行,这有助于优化执行计划。
- 数据缓存:对于需要多次使用的中间数据,用户可以将其缓存到内存中,以加速后续计算。Spark的缓存机制智能地管理内存,根据需求自动调整存储策略。
- 数据输出:处理后的结果可以保存到文件系统、数据库或实时流中。Spark支持多种输出格式,包括文本、Parquet、JSON等,方便与其他系统集成。
三、Spark在实际应用中的优势
Spark已被广泛应用于各行各业:
- 金融行业:银行和保险公司使用Spark进行实时欺诈检测和风险分析,通过处理海量交易数据,快速识别异常模式。
- 电商领域:企业利用Spark分析用户行为数据,实现个性化推荐和库存优化,提升用户体验和运营效率。
- 医疗健康:研究机构采用Spark处理基因组数据或医疗记录,加速疾病预测和药物研发过程。
- 物联网(IoT):在智能家居或工业物联网中,Spark Streaming能够实时处理传感器数据,实现设备监控和预警。
四、总结
Spark作为大数据处理的核心框架,以其高速、灵活和易用的特点,帮助企业高效地挖掘数据价值。随着人工智能和实时分析的普及,Spark的未来发展将更加注重与云平台、深度学习框架(如TensorFlow)的集成。对于数据工程师和科学家来说,掌握Spark是应对大数据挑战的关键技能。通过合理利用Spark的分布式计算能力,用户可以构建可扩展的数据管道,推动业务创新和决策优化。