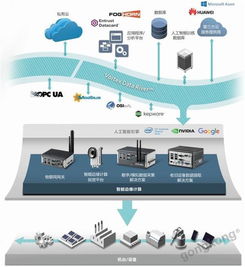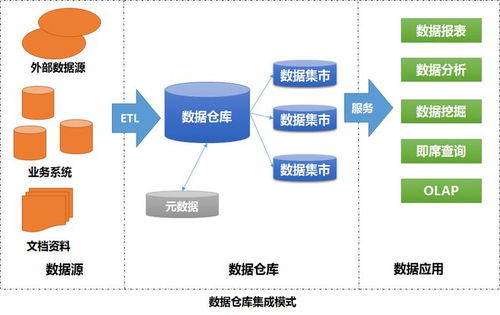
在数据驱动决策的时代,数据模型的治理已成为企业技术架构的核心环节。大淘宝作为国内领先的电商平台,其数据规模庞大、业务场景复杂,数据模型治理的挑战与重要性尤为突出。本文旨在分享大淘宝技术团队在数据模型治理,特别是数据处理阶段的阶段性实践经验与思考。
一、数据处理的挑战与目标
大淘宝的数据处理面临多重挑战:数据源多样,包括用户行为日志、交易记录、商品信息、广告投放等,格式不一、质量参差不齐;数据规模巨大,每日增量数据达到PB级别,对实时性与准确性要求极高;第三,业务需求快速迭代,数据模型需要灵活适应变化。因此,数据处理阶段的核心目标在于:确保数据从采集到使用的全链路中,实现高效、准确、一致和可扩展的处理,为上层数据模型提供高质量的基础。
二、阶段性实践:从原始数据到可信数据
在近期的治理工作中,大淘宝技术团队聚焦数据处理的关键环节,采取了分阶段的优化策略:
- 数据采集与接入标准化:统一了数据采集协议和接入规范,通过自研的日志采集工具和流式数据管道,实现了多源数据的实时汇聚。例如,针对用户行为数据,建立了标准化的埋点体系,减少数据歧义和丢失。
- 数据清洗与质量监控:开发了自动化数据清洗框架,包括去重、纠错、格式转换等流程。引入实时质量监控系统,对数据完整性、一致性和时效性进行多维检测,一旦发现异常,立即触发告警和修复机制。这显著提升了数据可信度,减少了因脏数据导致的模型偏差。
- 数据处理流水线优化:基于Flink和Spark等计算引擎,重构了批流一体的数据处理流水线。通过动态资源调度和计算优化,处理效率提升了约30%,同时降低了成本。团队还探索了数据湖架构的应用,将原始数据与处理后的数据分层存储,提高了数据复用性和灵活性。
- 元数据管理与血缘追踪:建立了全面的元数据管理系统,记录了数据从源头到应用的完整血缘关系。这不仅帮助团队快速定位数据问题,还支持影响分析,当上游数据变更时,能及时通知下游用户,避免业务中断。
三、成效与反思
通过阶段性治理,大淘宝在数据处理方面取得了初步成效:数据质量指标(如准确率、及时率)平均提升了20%,数据处理延迟降低了50%,团队协作效率因标准化而大幅提高。治理之路仍在继续。反思当前实践,我们认识到数据处理需与业务场景更紧密结合,例如,针对个性化推荐或风控等高频场景,需进一步优化实时处理能力。随着AI技术的融入,数据处理环节也开始探索智能化清洗和异常检测,以应对未来更复杂的挑战。
四、未来展望
大淘宝技术团队将持续深化数据模型治理,特别是在数据处理阶段,计划推进以下方向:一是强化数据安全与隐私保护,在高效处理的同时确保合规;二是推动数据资产化,通过更精细的数据分层和标签体系,提升数据价值;三是拥抱云原生和Serverless架构,实现弹性伸缩和成本优化。我们相信,通过持续的治理创新,数据处理将为淘宝生态的智能进化奠定更坚实的基础。
数据处理是数据模型治理的基石。大淘宝的阶段性分享表明,只有夯实数据处理环节,才能构建出可靠、高效的数据模型,最终驱动业务增长与用户体验提升。这条路虽充满挑战,但每一步都值得深耕。